2023. 9. 1. 14:06ㆍDevelopment
아마 스프링 프레임워크 기반 개발을 하시는 분들 중에 JPA를 사용한 적이 없는 분들은 없을 것이라고 생각해요. 그 정도로 널리 쓰이고, 쉽고 그리고 강력하죠.
너무나 편리하게 만들어져서, 우리 개발자들은 JPA와 JDBC, 그리고 관련 데이터베이스 기술을 엄격하게 구분하지 않아도 개발을 진행할 수 있어요.
하지만 더 자세하게 알수록 개발자로서 가치가 올라가고, 더 디테일한 개발을 할 수 있어요.
우리가 개발할 때 CPU, 메모리같은 하드웨어 구조를 직접 사용하지 않지만 컴퓨터 구조를 배우는 이유랑 똑같아요.
하드웨어 구조를 몰라도 개발을 할 수 있지만, 하드웨어의 구조를 알고, 소프트웨어와 상호작용하는 과정을 배워가면서 더 수준 높은 개발을 할 수 있기 때문이죠.
개인적인 일화인데 소프트웨어 마에스트로 활동을 하면서 멘토님께서 말씀해 주신 것이 있어요.
내가 사용하는 기술을 정확히 구분하고 학습하는 것이 개발에도 중요하지만 프로젝트 간 소통에도 큰 도움을 준다고 하셨어요.
한때 프로그래밍 언어와 프레임워크도 구분하지 못했던 부끄러운 시절을 생각하며 개발에 직접 사용 되는 것이 아니어도 여러가지 배우려고 노력하고 있어요.
다시 본론으로 들어가 오늘은 자바, 그리고 스프링 기반의 데이터베이스 접근 그리고 제어 기술에 대해 다루어보려고 해요.
주요 내용은 JDBC, JPA, Hibernate, 그리고 Spring Data JPA이고, 너무 깊게 들어가기 보다는, 각각의 역할과 구분, 그리고 관계에 초점을 두고 큰 틀을 설명할게요.
소프트웨어의 흐름 대로 데이터베이스와 가까운 곳부터 사용자와 가까워지는 방향으로 설명할 예정이에요.
1. JDBC - Java DataBase Connectivity
2. JPA - Java Persistent API
3. Hibernate - Implementation of JPA
4. Spring Data JPA - Convenient CRUD Library
1. JDBC - Java DataBase Connectivity
JDBC는 자바와 데이터베이스를 연결해주는 다리 역할을 해요.
아래 그림과 같이 JDBC는 사용자와 데이터베이스 사이에서 중개자 역할을 하는 것을 볼 수 있어요.
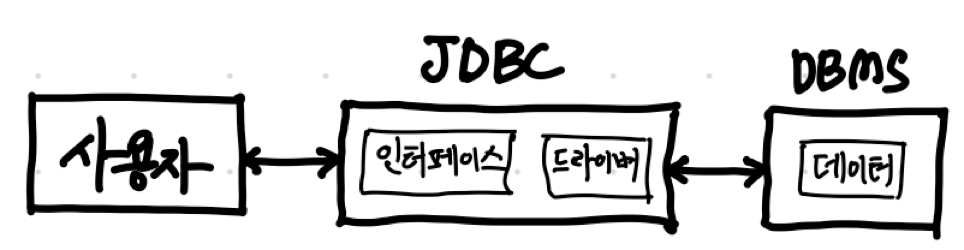
드라이버는 데이터베이스 정보를 토대로 연결 객체를 만들고, 이 드라이버를 통해 사용자는 데이터베이스 접근과 제어를 할 수 있어요.
하지만 어떤 개발자는 MySQL을 사용하고, 어떤 개발자는 Oracle을 사용해서 개발해요. 하지만 데이터베이스에 따라 연결 방법도 다르고 사용 방법도 다른데 어떻게 통일된 방법으로 개발을 할 수 있을까요?

기본적으로 JDBC는 다양한 DBMS에 대한 연결을 지원해요.
데이터베이스 연결은 언어마다 다르지만, JDBC의 드라이버가 알아서 연결을 해줘서 개발자는 신경 쓸 필요 없이 자신이 사용하는 DBMS의 드라이버를 사용하면 돼요.

하지만 객체 지향이라는 자바의 특성에 따라 JDBC는 드라이버를 추상화해서 인터페이스로 제공해요. 자신이 어떤 DBMS를 사용하는지 명시만 해주면 알아서 DBMS에 맞는 연결 객체를 사용할 수 있어요.
즉, JDBC는 드라이버를 추상화해서 인터페이스를 제공해요. 사용자가 어떤 DBMS를 사용하는 지와 상관 없이 인터페이스만으로 DBMS에 연결하고 제어할 수 있어요.

정리하자면 JDBC는 데이터베이스 환경과 독립적으로 자바 환경에서 데이터베이스를 통일된 방법으로 사용할 수 있는 기준을 제공해요.
2. JDBC - Java Persistent API
JPA는 JDBC에서 얻은 연결 객체를 통해 ORM 방식으로 데이터베이스를 사용할 수 있게 해주는 표준 인터페이스예요.
예를 들어 아래와 같은 Student 테이블이 있다고 가정해볼게요.

id를 기본키(Primary Key)로 가지고 있고, 이름과 나이, 그리고 전공으로 구성된 아주 간단한 구조의 테이블이에요.
만약 JDBC를 이용해 데이터를 얻어오면, 아래와 같은 쿼리와 결과를 볼 수 있어요.
JDBC
SELECT * FROM student WHERE id = 1;[1, "달맹", 22, "software"]각각의 컬럼은 그저 0번째 데이터, 1번째 데이터 등으로 표현돼요.
데이터의 특징을 살리지 못하고 그냥 선형 데이터로만 취급되죠.
JPA
SELECT s FROM Student s WHERE s.id = 1;Student(id=1, name="달맹", age=22, major="software")하지만 JPA를 이용하면 결과가 자동으로 객체로 매핑(Mapping)돼서 객체 지향적으로 데이터의 특징을 온전히 가질 수 있어요.
이 객체를 그대로 수정해서 데이터베이스에 반영할 수도 있고, 다른 객체와 연관시켜 관계를 표현할 수도 있어요.
이와 같이 자바의 객체 지향 언어라는 특성과 맞게 데이터도 객체로 다룰 수 있게 해줘요.
다음으로 JPA의 핵심적인 개념 중에 영속성 컨텍스트(Persistence Context)가 있어요.
성능 향상 및 사용의 편리성을 위해 사용자와 데이터베이스 사이에 존재하는 임시 데이터 저장소예요.
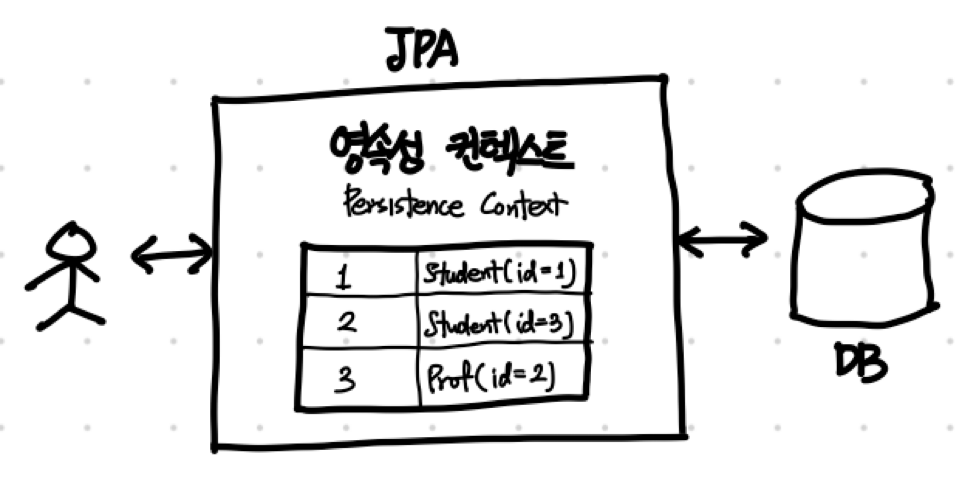
데이터 조회에 따른 영속성 컨텍스트의 역할을 간단하게 살펴볼게요.
- 사용자는 데이터를 조회한다.
- 우선 영속성 컨텍스트에 조회하고자 하는 객체가 있는지 확인한다.
- 찾고자 하는 데이터가 없으면 데이터베이스에서 데이터를 가져온다. 데이터 조회가 끝난 후, 영속성 컨텍스트에 저장하여 관리한다.
- 찾고자 하는 데이터가 있으면 영속성 컨텍스트에서 데이터를 가져온다.
데이터베이스에서 데이터를 가져오는 것은 외부와 통신하는 과정이어서 다소 무거운 작업이에요. 그래서 JPA(애플리케이션)에서 관리하는 임시 데이터베이스(영속성 컨텍스트)를 마련해서 최대한 무거운 작업을 없애려는 노력이죠.
컴퓨터 구조로 예를 들면, 보조기억장치에 가장 많은 데이터를 저장할 수 있지만 접근하는 시간이 오래 걸리기 때문에 주기억장치(메모리)를 두었는데, 이 마저도 마음에 안 들어서 레지스터, 캐시 메모리 등을 CPU와 가깝게 두어 어떻게든 성능을 높이려는 것이죠.
영속성 컨텍스트는 데이터 임시 저장소 기능 이외에도 다양하고 강력한 기능이 많아요. 그리고 강력한 기능만큼 알아야 할 것도 많아요. 영속성 컨텍스트에 대한 것을 여기에 적기에는 글의 주제를 벗어나는 것 같아서 적지 않았어요.
정리하자면, JPA는 JDBC가 가지고 있는 연결 객체를 이용하여 데이터를 조회하고, 데이터를 객체로 바꿔주는 역할을 해요. 그리고 영속성 컨텍스트를 통한 다양한 데이터 객체 관리 기능을 제공해요.
하지만 주의해야 하는게, JPA는 인터페이스예요. ORM을 이용한 이용 가이드라인(인터페이스)을 제시할 뿐, 내부 구현은 되어있지 않아요.
3. JDBC - Java Persistent API
앞서 설명한 내용에 따르면 JPA는 인터페이스이고, ORM을 이용한 이용 가이드라인만 제시할 뿐, 내부 구현은 되어있지 않다고 했어요.
하이버네이트(Hibernate)는 JPA의 내부 구현을 담당하고 있어요.

아래 그림으로 JPA와 하이버네이트의 차이를 이해해볼게요.
(실제 구현과 많이 다르고, 그저 이해를 위해 작성한 가짜 코드입니다.)
JPA
public interface JPAInterface{
Object findById(ID id);
}Hibernate
public class JPAInterfaceImpl implements JPAInterface{
@Override
public Object findById(ID id){
Data data = JDBC,executeQuery("SELECT * FROM ... ");
return dataToObject(data);
}
}우리는 객체 지향의 추상화에 따라 우리는 JPA를 사용하고 있는 것처럼 느끼지만, 내부적으로는 구현체인 하이버네이트를 사용하고 있다는 것이죠.
하이버네이트는 어디까지나 JPA의 구현체 중 하나예요.
만약 하이버네이트가 나랑 잘 안맞다 싶으면 다른 구현체를 쓰면 돼요.
저는 지금까지 하이버네이트 밖에 써보지 않았지만, EclipseLink, OpenJPA, TopLink 등 다양한 JPA 구현체가 있다고 하네요.

4. Spring Data JPA
아마 Spring Data JPA를 이용하시는 분이 가장 많을 것 같아요.
이름이 비슷해서 JPA와 Spring Data JPA를 헷갈려 하는 분들이 많아요.
Spring Data JPA는 JPA를 더 편리하게 사용할 수 있도록 하는 라이브러리예요.
주요 기능은 Repository 기반의 CRUD 처리를 위한 공통 인터페이스를 제공해요.
Spring Data JPA Repository
findAll();
findById(Long id);
findByUsername(String username);
.
.
.
findByIdOrderByUsernameAsc(Long id);
.
.
.메소드 이름에는 몇몇 규칙이 있어요.
find [조건] [정렬] ...위 규칙에 맞추어 메소드를 Repository 인터페이스에 정의하면 알아서 처리를 해줘요. 내부 구현은 Spring Data JPA가 내부적으로 처리해줘서 규칙에 맞게 정의만 하면 돼요.
아래는 규칙에 맞게 작성한 메소드 이름이에요.
findByUserIdAndUsernameAndAgeLessThanOrderByTimeDesc(Long userId, String username, Integer age);메소드 이름이 좀 길지만(...) 규칙이 간단해서 직관적으로 읽을 수 있죠?
위 메소드는 내부적으로
SELECT * FROM table_name WHERE user_id = {사용자 아이디} AND username = {사용자 이름} AND age < {사용자 나이} ORDER BY time DESC;으로 변환되어 DBMS에 전해져요.
규칙이 간단해서 외우고 있지 않아도 영어만 할 수 있다면 직관적으로 작성하면 대부분 작동이 돼요. 만약 규칙을 몰라도
https://docs.spring.io/spring-data/jpa/docs/current/reference/html/#repositories.query-methods
에 다양한 사용법을 제시하고 있으니 참고해도 돼요.
하지만 기본적으로 제공하지 않는 복잡한 쿼리를 작성해야 할 때도 있죠. 이럴 때를 위해 Spring Data JPA는 @Query 어노테이션을 활용하여 쿼리를 사용할 수도 있어요.
이때 사용하는 쿼리는 JPQL로, 객체 지향용 쿼리라고 생각하면 편해요.
@Query("select distinct c from Category c join fetch c.problemCategories p join fetch p.problem")
List<Category> findAllWithFetchJoin();위와 같이 메소드 이름은 원하는 대로 정하고, @Query 어노테이션에 JPQL 쿼리를 작성해서 활용할 수도 있어요.

보통 간단한 쿼리는 Spring Data JPA에서 제공하는 기본 메소드를 이용하고, 조인같은 복잡한 쿼리에 대해선 @Query 어노테이션으로 JPQL을 사용해요.
우리는 그저 Repository에 정의한 메소드를 호출하면 JPA, 하이버네이트, 그리고 JDBC가 총 출동해서 알아서 쿼리를 처리한 뒤, 결과를 반환해줘요.
따라서 우리는 Spring Data JPA로 내부 연결 객체, 매핑, 쿼리 전부 신경쓰지 않고, Repository 하나로 전부 해결할 수 있어요. 매우 강력한 기능이죠.
정리하자면, Spring Data JPA는 위 모든 기능을 편하게 사용하기 위해 존재하는 라이브러리예요. Repository 기반의 공통 CRUD 처리를 지원하고, 규칙에 맞는 메소드 정의만으로도 해당 기능을 사용할 수 있어요.
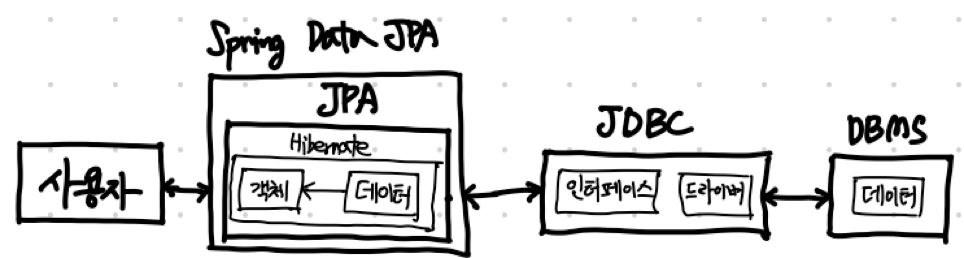
이상 JDBC, JPA, Hibernate, 그리고 Spring Data JPA에 대한 모든 설명이 끝났어요.
자세한 내부 구현보다는 위 요소들이 어떻게 상호작용하고 어떤 역할을 맡고 있는지 파악하는 것이 중요해요.
그래야 문제가 생겼을 때, 어디서 문제가 생겼는지 정확하게 파악하고 유연하게 대처할 수 있어요.
제 글이 많은 도움이 되었길 바라며,
긴 글 봐주셔서 감사합니다!
멋진 개발자가 되기 위해 더 열심히 달리겠습니다!
- 달맹 -
'Development' 카테고리의 다른 글
| JWT 기반 인증 5편 - 스프링 시큐리티 JWT 인증 · 인가 구현 (3) (0) | 2023.09.08 |
|---|---|
| JWT 기반 인증 4편 - 스프링 시큐리티 JWT 인증 · 인가 구현 (2) (1) | 2023.09.07 |
| JWT 기반 인증 3편 - 스프링 시큐리티 JWT 인증 · 인가 구현 (1) (0) | 2023.09.05 |
| JWT 기반 인증 2편 - 스프링 시큐리티 JWT 설계 (0) | 2023.09.05 |
| JWT 기반 인증 1편 - JWT란? (0) | 2023.09.04 |