2024. 3. 10. 21:29ㆍDevelopment
안녕하세요, 이 게시물을 마지막으로 프롬프트 공학을 마무리 해보려고 해요.
오늘은 번외 목차도 준비했으니 꼭 끝까지 봐주세요!
이전 게시물을 보지 않으셨다면 차례대로 보는 걸 추천드려요.
Prompt Engineering: ChatGPT와 대화하기 1편
안녕하세요, 오늘은 ChatGPT 같은 LLM을 사용할 때 알면 좋은 내용인 프롬프트 공학(Prompt Enginnering)에 대해 다뤄보려고 해요. ChatGPT를 사용할 때, "Message ChatGPT..."에 물어보고 싶은 말들을 열심히 쓰
dalmeng-commeng.tistory.com
Prompt Engineering: ChatGPT와 대화하기 2편
안녕하세요, 이번 시간에는 저번 시간에 이어 프롬프트 공학을 다뤄볼 거예요. 이번 게시물은 아래 게시물과 이어지는 내용이니 안 보신 분은 보는 걸 추천드려요. Prompt Engineering: ChatGPT와 대화
dalmeng-commeng.tistory.com
Prompt Engineering: ChatGPT와 대화하기 3편
안녕하세요, 이번 시간도 저번 게시물에 이어 프롬프트 공학을 다뤄볼 거예요. 이번 게시물은 아래 게시물과 이어지는 내용이니 안 보신 분은 보는 걸 추천드려요. Prompt Engineering: ChatGPT와 대화
dalmeng-commeng.tistory.com
이 글은 GPT 모델을 만든 OpenAI 사의 프롬프트 공학 가이드를 참고했어요.
https://platform.openai.com/docs/guides/prompt-engineering
1. 지시문을 명확하게 작성하라 - Write clear instructions
2. 참고할 수 있는 자료를 제공하라 - Provide Reference Text
3. 간단한 작업으로 나누어 진행하라 - Split complex tasks into simpler subtasks
4. 모델에게 생각할 시간을 주어라 - Give model time to think
5. 외부 도구를 활용하라 - Use External Tools
[번외] 프롬프트를 프롬프트로 - Proofread Prompt using LLM
이 글에서 제가 사용한 모델은 모두 GPT-3.5와 GPT-4를 섞어서 사용했어요.
5. 외부 도구를 활용하라 - Use External Tools
언어 모델은 복잡하고 긴 수학적 계산을 잘 하지 못해요. 따라서 그런 작업은 편하게 할 수 있도록 외부 도구를 제공해주는 것이 좋아요.
또한, 모델은 기본적으로 기억력이라는 개념이 없기 때문에 외부 도구를 활용해 기억력을 부여해줄 수도 있어요.
5 - 1. 복잡한 작업은 외부 함수를 사용하도록 시키자 - Use code execution to perform more accurate calculations or call external APIs
사용자 아이디에서 사용자 이름과 나이를 구하는 간단한 예시를 만들어보았어요.
사용자 아이디는 "{username을 알파벳 한 글자 씩 미룬 것}-{생년월일을 거꾸로 쓴 것}" 형식으로 이루어져 있어요.
이를 파싱하고 얻은 생년월일을 토대로 나이를 구해야 해요.
여기서 사용자에 대한 정보를 구하는 함수 extract_info는 미리 작성해두었고, GPT가 만들지 않고 이 함수를 사용하도록 지시했어요.

사용자 정보 추출 작업은 추론 작업도 아니고 구현 문제이기 때문에 작성된 함수를 사용했고, 나이를 추론하는 작업만 맡겼어요.
이와 같이 직접 작성한 함수를 사용하게 할 수도 있다는 점을 참고해주세요.

함수 뿐만 아니라 외부 API도 호출할 수 있다는 것을 보니 HTTP 요청 명세를 알려주면 API도 활용할 수 있다는 거 같아요.
5 - 2. 기억력 유지를 위해 데이터베이스를 사용하자 - Use embeddings-based search to implement efficient knowledge retrieval
앞서 말했듯이, 모델은 기억력이라는 개념이 없죠?
따라서 데이터베이스를 활용하여 기억력을 유지시켜줘야 해요.
특히, LLM과 궁합이 좋은 방법은 벡터 데이터베이스(Vector Database)를 활용하는 거예요.
벡터 기반 검색을 지원하는 벡터 데이터베이스를 활용하면 다루고자 하는 내용과 관련된 데이터를 가져올 수 있어요.
원리를 간단하게 설명해볼게요.
우선 문맥 정보를 포함하여 문장을 벡터로 변환할 수 있다는 것을 이해하고 시작해야 해요. 이 작업을 임베딩(Embedding)이라고 하는데, 문장을 고차원 벡터로 변환하는 작업을 뜻해요.
데이터들을 임베딩해서 벡터 데이터베이스에 저장해둔다음, *코사인 유사도(Cosine Similarity) 같은 메트릭을 활용해서 문맥적으로 비슷한 데이터를 가져와요.
* 코사인 유사도(Cosine Similarity)란?
두 벡터가 얼마나 유사한지 확인하는 메트릭으로, 내적을 활용해서 두 벡터 사이의 각을 구한다.
완전히 일치한다면 두 벡터 사이의 각은 0도로, 1의 값을 갖는다. 만약 정반대라면 두 벡터 사이의 각은 180도로, -1의 값을 갖는다.
따라서 두 벡터가 얼마나 유사한지 닫힌 구간 [-1, 1] 내의 값으로 표현하는 방법이다.
예를 들어, 벡터 데이터베이스에 세 개의 문장이 있다고 가정해볼게요.
1. 아버지가 편찮으셔서 너무 슬퍼.
2. 어제 친구랑 싸웠는데, 어떻게 화해를 해야 할 지 모르겠어.
3. 저번 주에 바다 여행을 다녀왔는데 너무 재미있었어.
사용자가 "저번에 우리 아버지에 대한 이야기를 했었는데, 무슨 일이었는지 기억나?"라고 물어봤다고 가정해볼게요.
데이터베이스를 활용하지 않는다면 아래와 같이 답변할 거예요.

솔직히 모르는 걸 모른다고 해서 다행이네요.
데이터베이스에 따르면 아버지는 지금 편찮으신 상태인데, 만약 아는 척 "맞다! 아버지 저번에 승진하셨다며!" 와 같은 말을 했다가는 큰일 나겠죠?
이제 벡터 데이터베이스를 활용해서 관련된 데이터를 가져와볼게요.
| 발화(Transcript) | 코사인 유사도(Cosine Similarity) |
| 아버지가 편찮으셔서 너무 슬퍼. | 0.89 |
| 어제 친구랑 싸웠는데, 어떻게 화해를 해야 할 지 모르겠어. | 0.65 |
| 저번 주에 바다 여행을 다녀왔는데 너무 재미있었어. | 0.64 |
코사인 유사도는 클수록 좋다고 했죠? 따라서 사용자의 발화 "저번에 우리 아버지에 대한 이야기를 했었는데, 무슨 일이었는지 기억나?"에 대해 가장 유사한 문장은 코사인 유사도가 가장 큰 "아버지가 편찮으셔서 너무 슬퍼."라는 것을 알 수 있어요.
이 문장을 활용하여 대답하라고 GPT에게 지시해볼게요.
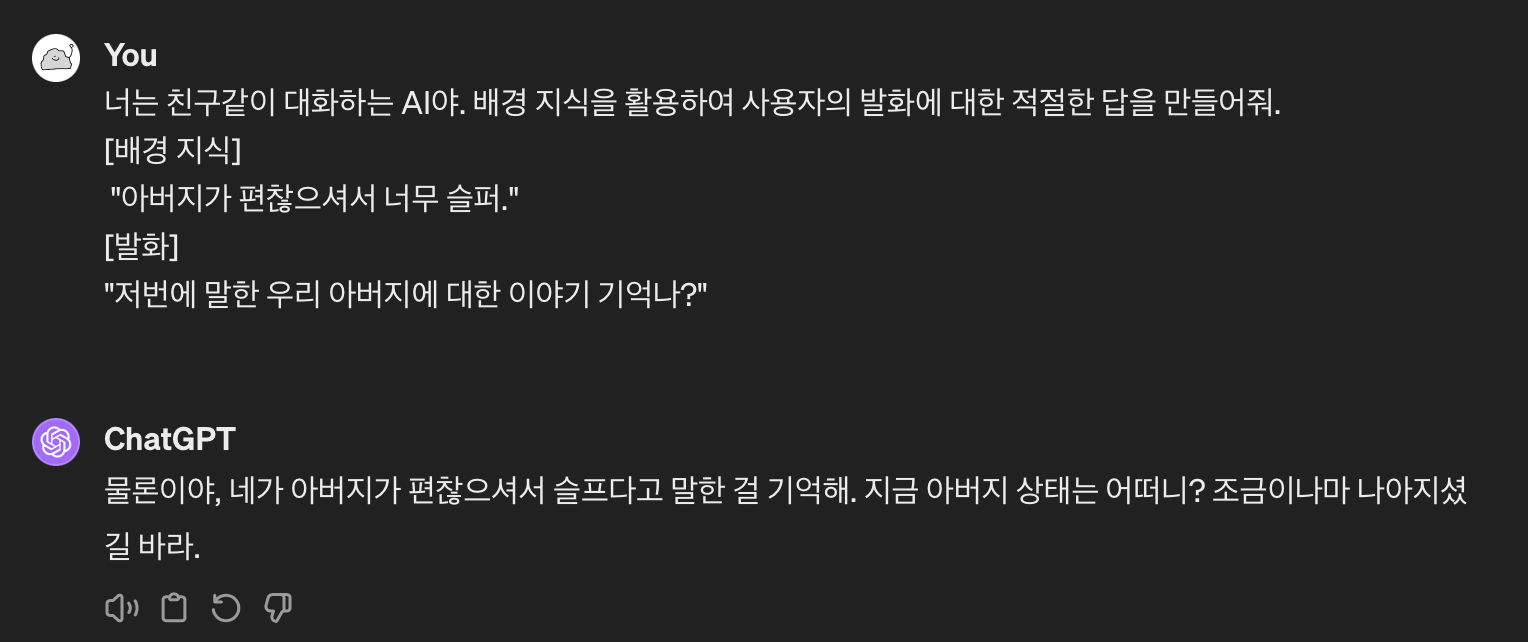
아버지가 편찮으시다는 기억을 배경 지식으로 주니 훨씬 좋은 대답을 만들어낸 것을 알 수 있죠?
이와 같이 데이터베이스 같은 저장소에서 관련 정보를 검색해서 그 정보를 활용하여 새로운 답변을 만들어 내는 기술을 RAG(Retrieval Argumented Generation, 검색 증강 생성)이라고 해요.
이 예시에서는 RAG의 저장소로 벡터 데이터베이스를 활용하여 LLM에게 기억력이라는 개념을 부여했어요.
데이터베이스 말고도 대규모 문서를 문장이나 문단 단위로 파싱해서 벡터 데이터베이스에 넣은 후, RAG를 하는 방법도 많이 쓰여요.
관련된 데이터를 잘 가져오기 위해서는 저장되는 데이터의 퀄리티도 중요하고 임베딩 모델 자체의 성능, 차원 등 여러 요소가 정확성에 영향을 끼쳐요.
따라서 제작하는 서비스의 종류, 특성에 따라 임베딩 모델은 어떤 것을 사용할지, 차원은 어떻게 정할지, 파인 튜닝(Fine-Tuning)은 어떻게 할 것인지 등 세세하게 정해야 높은 정확도의 RAG를 구현할 수 있어요.
[번외] 프롬프트를 프롬프트로 - Proofread Prompt using LLM
이 내용은 제가 ChatGPT를 활용하면서 배운 방법인데, 좋은 프롬프트를 작성하는 데 큰 도움이 돼서 알려드려요.
솔직히 자신은 자기가 가장 잘 안다고, GPT에게 프롬프트를 교정해달라고 요청할 수도 있어요.

그러면 LLM이 이해하기 쉽도록 프롬프트를 수정해줘요.

저는 왜 그렇게 변경했는지 이유도 함께 작성하라고 했는데, 좋은 프롬프트가 갖추어야 할 요소들을 준수해서 수정해준 것을 알 수 있어요.

하지만 프롬프트의 큰 구조까지는 잘 변경해주지 않더라고요. 따라서 기본적인 프롬프트 공학론을 활용해서 적당히 잘 알아듣게 구성한 후, GPT에게 맡겨서 보완하는 방식이 좋을 것 같아요.
참고로, LLM은 한국어보단 영어를 더 잘 이해해요. 따라서 복잡한 과정이나 높은 수준의 추론을 해야 한다면 영어로 프롬프트를 작성하는 걸 추천해요. 사실 이 작업도 아래와 같이 GPT에게 맡기면 돼요.
Proofread below prompt in English to make LLM easier to understand.
번역 : LLM이 더 잘 이해할 수 있도록 프롬프트를 영어로 수정해줘.
심지어 프롬프트에 아래와 같이 영어와 한국어를 섞어서 써도 GPT는 찰떡같이 알아듣고 교정해주니 이 활용법은 꼭 익혀두세요!
Proofread below prompt in English to make LLM easier to understand.
[Prompt]
아래 대화의 핵심 topic을 추출해줘. If 대화 have 여러 개의 주제, 파이썬 리스트 형식으로 만들어줘.
↓
To make your prompt clearer and more understandable for an LLM, here's a revised version in English:
"Please extract the main topics from the following conversation. If the conversation contains multiple topics, present them in the form of a Python list."
아주 긴 프롬프트 공학에 대한 이야기가 끝났어요.
솔직히 말하고 싶은 내용이 더 많지만, 아주 중요한 핵심 정도만 소개했어요.
(사실 저도 계속 좋은 프롬프트를 작성하기 위해 계속 노력하고 있답니다.)
한 번에 좋은 프롬프트를 작성하기는 매우 힘들어요. 만들고 보완하는 과정을 반복적으로 거쳐야 비로소 좋은 프롬프트를 만들 수 있어요.
제가 알려드린 여러가지 프롬프트 공학 방법론을 활용하여 GPT를 최대한 열심히 굴리길 바라요.
LLM은 과거와 비교할 수 없는 엄청난 혁신이고 세상을 바꿀 기술이에요.
앞으로 더 발전할 것이고 그 기술을 활용하는 것은 저희 손에 달렸어요.
제대로 활용하면 생산성을 말도 안 되게 향상시킬 수 있는 좋은 도구이니깐 여기서 그치지 않고 좋은 프롬프트를 작성하는 연습을 계속 해보는 것을 추천할게요.
여기까지 프롬프트 공학에 대한 내용을 마치고, 더 좋은 내용으로 돌아오도록 할게요.
감사합니다.
제 글이 많은 도움이 되었길 바라며,
긴 글 봐주셔서 감사합니다!
멋진 개발자가 되기 위해 더 열심히 달리겠습니다!
- 달맹 -
'Development' 카테고리의 다른 글
| 로그 공유 시스템 만들기 : AWS EKS & EFS (0) | 2024.03.12 |
|---|---|
| Prompt Engineering: ChatGPT와 대화하기 3편 (0) | 2024.03.10 |
| Prompt Engineering: ChatGPT와 대화하기 2편 (0) | 2024.03.10 |
| TOPCIT 체험기 [문제 예시, 유형, 후기] (0) | 2024.03.10 |
| Prompt Engineering: ChatGPT와 대화하기 1편 (0) | 2024.03.09 |